|
This PASCAL funded pump-priming project aims to bring continuous and uncertain interaction methods into both brain-computer interfaces, and to the interactive exploration of song spaces. By treating the interaction problem as a continuous control process, a range of novel techniques can be brought to bear on the BCI and song exploration problem.
EEG brain-computer interfaces suffer from high noise levels and heavily-lagged dynamics. Existing user interface models are inefficient and frustrating for interaction. By explictly taking the noise and dynamical properties of the BCI control signals into account, more suitable interfaces can be devised.
The song-exploration problem involves navigation of very high-dimesional feature spaces. The mapping from these spaces to user intention is uncertain. Uncertain and predictive displays, combined with intelligent navigation controls, can aid users in intuitively navigating musical spaces.
This work is in collaboration with the IDA group at Fraunhofer First and the Intelligent Signal Processsing Group at DTU.
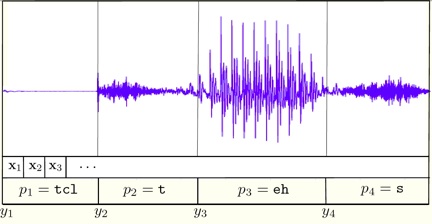
Research on large margin algorithms in conjunctions with kernel methods has been both exciting and successful. While there have been quite a few preliminary successes in applying kernel methods for speech applications, most research efforts have focused on non-temporal problems such as text classification and optical character recognition (OCR). We propose to design, analyze, and implement learning algorithms and kernels for hierarchical-temporal speech utterances. Our first and primary end-goal is to build and test thoroughly a full-blown speech phoneme classifier that will be trained on millions of examples and will achieve the best results in this domain. This project is a joint reseach effort between The Hebrew University and IDIAP.
|
This project is focused on multi-task learning (MTL) for the purposes of developing optimisation methods, statistical analysis and applications. On the theoretical side, we propose to develop a new generation of MTL algorithms; on the practical side, we will explore applications of these algorithms in the areas of marketing science, bioinformatics and robot learning. As an increasing number of data analysis problems require learning from multiple data sources, MTL should receive more attention in Machine Learning and we expect that more researchers will work on this topic in the coming years.
We are particularly interested in optimisation approaches to MTL. In particular, our proposed approach will: 1) allow one to model constraints among the tasks; 2) allow semi-supervised learning -- only some of the tasks have available data but we still wish to learn all tasks; 3) lead to efficient optimisation algorithms; 4) subsume related frameworks such as collaborative filtering and learning vector fields.
We consider reinforcement learning under the paradigm of online learning where the objective is good performance during the whole learning process. This is in contrast to the typical analysis of reinforcement learning where one is interested in learning a finally near-optimal strategy. We will conduct a mathematically rigorous analysis of reinforcement learning under this alternate paradigm and expect as a result novel and efficient learning algorithms.
We believe that for intelligent interfaces the proposed online paradigm provides significant benefits as such an interface would deliver reasonable performance even early in the training process.
The starting point for our analysis will be the method of upper confidence bounds which has already been very effective for simplified versions of reinforcement learning. To carry the analysis to realistic problems with large or continuous state spaces we will estimate the utility of states by value function approximation through kernel regression. Kernel regression is a well founded function approximation method related to support vector machines and holds significant promise for reinforcement learning.
Finally we are interested in methods for reinforcement learning where no or only little external reinforcement is provided for the learning agent. Since useful external rewards are often hard to come by, we will investigate the creation of internal reward functions which drive the consolidation and the extension of learned knowledge, mimicking cognitive behaviour.
|